Mein persönlicher Ansatz zum digitalen Archiv, hier einmal etwas eingehender beschrieben. Evtl. findet es jemand nützlich? Das ganze ist auf Linux-Systeme ausgerichtet, vom Prinzip funktioniert sollte es aber unter allen System umsetzbar sein, die Dateien/Ordner verwenden. Das ist auch die Grundidee, es soll völlig plattformunabhängig funktionieren. Ich mag Basteln am Computer – auch wenn ich beruflich nichts mit IT zu tun habe. Irgendwann stellte sich dann einmal die Frage, was mit alten Unterlagen (damals waren es tatsächlich u.a. noch Klassenarbeiten und später Oberstufen-Klausuren) passieren sollte. Kistenweise Aufheben wollte ich nicht, wegschmeißen aber irgendwie auch nicht. Es lag nahe, sie digital aufzuheben, die Originale brauchte ich fürs Gefühl nicht mehr, wenn ich alles digital archiviert hätte. Letztlich ist so ein digitales Archiv entstanden, was jetzt mehr als 15 Jahre alt ist und stetig weiter wächst. Anfangs mühsam mit irgendeinem Scan-Programm einzeln gescannt und als jpg-Dateienabgelegt, bin ich natürlich dann auch irgendwann mit dem Thema OCR in Kontakt gekommen. Und etwas später dann mit Linux.
Grundprinzipien
Im Internet finden sich ebenfalls einige Artikel zu dem Thema, insbesondere Blogeinträge von Leuten mit ähnlichen Gedanken fand ich spannend. Gedanken heißt in dem Fall:
- Die Unterlagen (meist Briefe im DIN A4 Format) sollen langfristig lesbar gespeichert werden (nicht 100 Jahre oder so, aber in 20 Jahren möchte ich sie schon gerne noch lesen können). Letztlich kommt man dann meist auf PDF. Djvu hatte ich auch mal probiert, bin aber wieder davon abgekommen. Wird nicht genug unterstützt.
- Platzsparend. Also: Unterlagen als Schwarz-Weiß Scan ablegen, optimieren. Das Archiv ist auch so schon groß genug (~30 GB aktuell, aber auch mit vielen nicht-Dokumenten)
- Durchsuchbar. Sprich: OCR soll natürlich benutzt werden, ich möchte mit einem entsprechenden Indexer (Recoll nutze ich dafür) Dinge finden können, bei denen ich mich nicht mehr an Dateinamen oder Speicherort erinnern kann. Um nach Dateien im Archiv anhand des Dateinamens zu suchen, nutze ich ganz einfach das Unix-Standardtool locate (mit etwas Bashscript-Hilfe, sodass je nach Befehl nur das Archiv durchsucht wird und nicht die ganze Platte).
- Unabhängig. Damit ist unabhängig von irgendwelchen Software(-Herstellern), Formaten, Dateisystemen, Datenbanksystem, Betriebssystemen usw. gemeint. Einfach Dateien in Ordnern, ganz simpel.
- Einfach. Sowohl beim Suchen (In den Ordnern nachschauen oder auch Recoll benutzen ist einfach, finde ich), als auch beim Befüllen. Im Internet finden sich Beschreibungen von (meiner Meinung nach) komplizierten Tag-Strukturen. Z.b. wurden Tags im Dateinamen abgelegt, und mit Sonderzeichen getrennt. Dann konnten sich alle Dateien in einem Ordner ansammeln und man kann einfach nach Tags durchsuchen. Das hat den Vorteil, dass man sich nicht entscheiden muss, ob man die Rechnung für die KFZ-Versicherung nun unter Auto ablegt oder unter Versicherungen. Das ist ein guter Ansatz. Aber hätte ich in den letzten 15 Jahren alles in einem (oder einer Hand voll) Ordner abgelegt, dann würde ich – glaube ich – aktuell nichts mehr gut finden. Die Disziplin, immer korrekte Tags zu vergeben (oder Tippfehler?), hätte ich vermutlich nicht gehabt. Ich habe mich daher einfach für Ordner entschieden, wie oben erwähnt. Das finde ich unheimlich einfach. Hin und wieder muss man für sich selber festlegen, ob man nun die Rechnungen für die Kasko-Versicherung eben unter Versicherungen verstaut oder im Auto-Ordner – aber man kann das auch ganz simple lösen, indem man einfach einen Softlink anlegt (oder meinetwegen Hardlink) und fertig. Mit der Zeit weiß ich aber einfach meist, wo ich Dinge ablege, die ich immer mal wieder brauche. Für alles, an das ich mich nicht erinnern kann, habe ich locate (die Dateisystem-Suche unter Linux) und wenn das immer noch nicht hilft, den Indexer, also recoll.
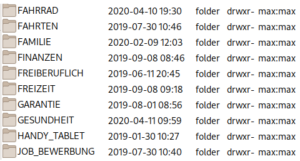
Hier eine beispielhafte Ordnerstruktur (nicht vollständig, der Privatsphäre wegen):
Die Dateien werden nach diesem Schema benannt:
JJJJ-MM-DD_Firma_oder_Organisation_etc_Titel_des_Dokuments.pdf
also z.b.
2019-10-14_TK_Versicherungsbescheinigung.pdf
Und die liegt dann in
VERSICHERUNGEN/Krankenversicherung/
Ich habe irgendwann einmal die groben Kategorie-Ordner in Großbuchstaben geschrieben, warum auch immer, aber das spielt eigentlich keine Rolle.
Archiv befüllen
Vor allem das Bewerkstelligen des einfachen Befüllens hat anfangs etwas Mühe gekostet, denn ich habe auf die Schnelle kein Programm gefunden, was Dokumente scannt, auf schwarz-weiß optimiert, OCR durchführt und alles als PDF abspeichert – noch dazu, wenn ein Dokument aus mehreren Seiten besteht (z.B. Vorder- und Rückseite). Natürlich gibt es Tools, die das können, und noch viel mehr. Ich wollte es aber auch gerne auf der Kommandozeile haben, sodass ich einfach nur einen Befehl eingeben muss wenn das Papier im Scanner liegt, und der Rest wird erledigt. Dafür habe ich mir ein Python-Tool geschrieben, das genau das tut. Für komplexere Dokumente, mit Seiten im Querformat (die also nach dem Scannen gedreht werden müssen) und vielen Seiten nutze ich manchmal einfach Simple-Scan (und führe die OCR im Anschluss über ein anderes, selbst geschriebenes Script durch).
Der übliche Ablage-Stapel auf dem Schreibtisch muss dann nur noch einigermaßen regelmäßig durchgeschaut werden – unnötiges wandert in den Papiermüll, wichtiges wird eingescannt und wandert dann in den Papiermüll. Sehr wichtiges wird analog aufbewahrt, Bescheinigungen und so weiter, also Dinge, die man als Original aufheben möchte. Die landen dann eben doch in einem Ordner, aber dafür reichen mir inzwischen 2 Stück (einer für Privates, einer für Arbeit). Damit fällt das Papier-Archiv unheimlich schlank aus und ich habe alles, was dort im Ordner abgeheftet ist, auch vernünftig einscannt und durchsuchbar digital verfügbar.
Backup
Selbstverständlich braucht es eine regelmäßige Sicherung. Externe Festplatten, regelmäßig synchronisiert und an unterschiedlichen Stellen aufbewahrt, sollten hier für passable Sicherheit sorgen. Ich nutzte restic als Backup Software und habe 2 externe Festplatten die regelmäßig befüllt werden und an zwei völlig anderen Orten lagern, sodass selbst ein Wohnungs- oder Hausbrand mich höchstens ein paar Tage an Daten kosten würde (neben dem ganzen anderen Ärger).
Aktuelle Struktur
(mit filelight erstellt)